Der CSV-Importer benutzt dafür das Programm recode, welches auf dem Server installiert sein muss.
Ein CSV-Import besteht aus 3 Schritten:
Folgende Beispiele veranschaulichen die Möglichkeiten / Funktionen des CSV-Importers:
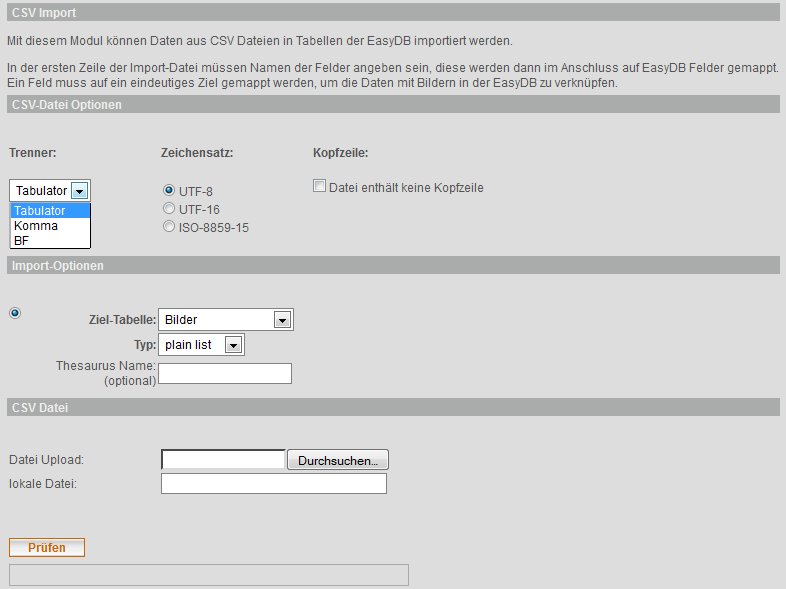
| 1 | Wählen Sie aus, welches Trennzeichen Ihre CSV-Datei benutzt. Wir empfehlen unbedingt Tabulator zu benutzen, da der Support für Komma eingeschränkt ist. Das Trennzeichen BF (Hexadezimal: bf c0 bf) wird von Imagefinder-Export-Dateien benutzt. |
| 2 | Geben Sie an, in welchem Zeichensatz Ihre CSV-Datei kodiert ist. Wenn Sie sich nicht sicher sind, probieren Sie ISO-8859-15 und danach UTF-8. |
| 3 | Geben Sie an, ob Ihre CSV-Datei eine Kopfzeile enthält. In der Kopfzeile können Sie Feldnamen der Zieltabelle verwenden, easydb versucht die Feldnamen zu finden und vereinfacht oder erspart Ihnen das Einstellen des Felder-Mappings im Verlauf des Imports. Wenn Sie keine Kopfzeile in dem CSV haben, so nennt easydb die Spalte spalte1, spalte2, usw. |
| 4 | Wählen Sie die Zieltabelle aus. |
| 5 | Wählen Sie den Typ der CSV aus. Hierbei wird zwischen zwei Typen "plain list" und "thesaurus" unterschieden. Bei plain list handelt es sich um eine einfache Liste mit Zeilen und Spalten. Bei "thesaurus" handelt es sich um eine hierarchische Liste mit Zeilen und Spalten. Die Hierarchie-Ebene wird je Zeile durch vorangestellte Tabulatoren bestimmt. |
| 6 | Prefix für den internal_tree_name welcher automatisch für jede Zeile eines Thesaurus-CSV-Importes erzeugt wird. |
| 7 | Nutzen Sie Durchsuchen…, um von Ihrem Computer eine CSV-Datei auszuwählen, die Sie auf den easydb-Server übertragen möchten. |
| 8 | Alternativ zu 7 können Sie hier einen kompletten Pfad zu der CSV Datei angeben, die schon auf dem easydb-Server liegt. |
| 9 | Klicken Sie auf Prüfen, wenn Sie alles ausgefüllt haben. Unter dem Button erscheint ein Fortschritts-Balken 10. |
easydb erkennt Texte nicht korrekt, die in Anführungszeichen stehen, d.h. wenn Sie Komma wählen und in Ihrem CSV eine Zeile wie beispielsweise Titel 1,"Beschreibung Beschreibung, Beschreibung 1",EASYDB_1 drinsteht, wird easydb die Felder hinter dem 2. Komma falsch trennen.
Nach erfolgreichem Import, geht easydb zu Schritt 2 über. Die CSV-Daten wurden zu diesem Zeitpunkt noch nicht in die Datenbank geschrieben.
Unsere Beispiel CSV-Datei sieht wie folgt aus (Download):
title description asset_code artist/name keyword1/name keyword2/name keyword3/name
Titel 1 Beschreibung 1 EASYDB_1 Artist A Schlagwort 1 Schlagwort 2 Schlagwort 3
Titel 2 Beschreibung 2 EASYDB_2 Artist A Schlagwort 4 Schlagwort 5 Schlagwort 6
Titel 3 Beschreibung 3 EASYDB_3 Artist B Schlagwort 7 Schlagwort 8 Schlagwort 9
Titel 4 Beschreibung 4 EASYDB_4 Artist B Schlagwort 1 Schlagwort 2 Schlagwort 3
Titel 5 Beschreibung 5 EASYDB_5 Artist C Schlagwort 4 Schlagwort 5 Schlagwort 6
Titel 6 Beschreibung 6 EASYDB_6 Artist C Schlagwort 7 Schlagwort 8 Schlagwort 9
Im 2. Schritt legen Sie das Feld-Mapping fest. Es werden die Felder der Tabelle angezeigt, die sie in Schritt 1 ausgewählt haben.
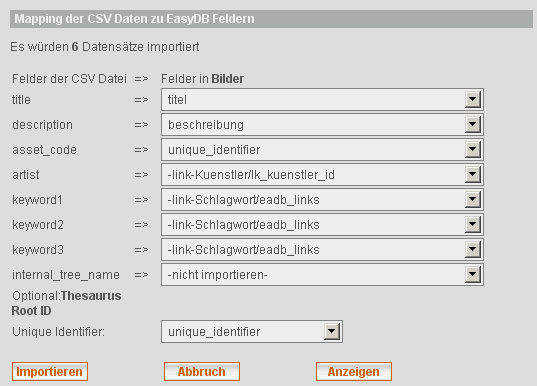
Wenn die Überschriften in der CSV-Datei den Spaltennamen in der Datenbank entsprechen werden diese automatisch zugeordnet und sind im Pulldown vorausgewählt.
In unserem Beispiel hat die Prüfung ergeben, dass Datensätze importiert würden, siehe 1. In Mapping haben wir für die CSV-Spalte title das Feld titel ausgewählt. Die Spalte description wird in das Feld beschreibung gemappt. Der asset_code wird in unique_identifier geschrieben.
Die Spalte artist wird über das Feld lk_kuenstler_id mit der Tabelle Kuenstler verknüpft. Die Spalte keyword1 wird mit der Tabelle Schlagwort verknüpft unter Verwendung der Link-Tabelle eadb_links. Für die erfolgreiche Verknüpfung müssen die folgenden Voraussetzungen gegeben sein:
Die Link-Tabelle muss ein Feld unique_identifier haben. Das Feld aus dem CSV wird mit unique_identifier abgeglichen. Nur wenn in der Link-Tabelle ein passender Eintrag in unique_identifier gefunden wird, wird eine Verknüpfung hergestellt, sonst wird die Verknüpfung übersprungen.
Das bedeutet, dass Sie sicherstellen müssen, dass alle Einträge in den Link-Tabellen bereits vorhanden sind. In unserem Beispiel bedeutet das, dass in der Tabelle Schlagwort die Schlagworte "Schlagwort 1", "Schlagwort 2", "Schlagwort 3" usw. enthalten sein müssen. In der Tabelle Kuenstler benötigen wir die Künstler "Artist A", "Artist B" und "Artist C".
Seit Version 4.0.259 werden Einträge die im CSV aber nicht in der Link-Tabelle vorhanden sind, automatisch angelegt. Mit Hilfe spezieller Überschriften im CSV kann beim Import entschieden werden mit welcher Spalte der Abgleich erfolgen soll (Syntax: "Tabelle/Spalte", z.B. "schlagworte/name"). Darüber hinaus ist es möglich in dedizierte Verknüpfungs-Tabellen zu importieren. Wählen Sie hierbei beim Mapping beispielsweise folgenden Eintrag aus:
Link: kategorien.unique_identifier/asset__kategorie
Ein Beispiel finden Sie hier.
Für die Haupt-Tabelle (in unserem Beispiel Bilder) können Sie den unique_identifier bestimmen. Dafür wählen Sie im Pulldown 2 die entsprechende Spalte aus. In unserem Beispiel nutzen wir asset_code zur eindeutigen Bestimmung unserer Einträge. asset_code wird in die Spalte unique_identifier geschrieben. Der unique_identifier ermöglicht es Ihnen in der Tabelle Bilder Updates vorzunehmen. Wenn Sie als unique_identifier - keiner = nur Insers – auswählen, werden alle Zeilen der CSV-Datei neu eingefügt. Mit angegebenen unique_identifier wird in der Tabelle nach einem entsprechenden Eintrag gesucht und ggfs. ein Update durchgeführt. Dabei werden nur die Spalten aktualisiert, die Sie im Mapping angegeben haben, alle anderen Spalten bleiben unberührt.
Ein weiteres Beispiel für Updates mittels unique_identifier finden Sie hier.
Klicken Sie auf Anzeigen, um eine Vorschau der Daten zu sehen:
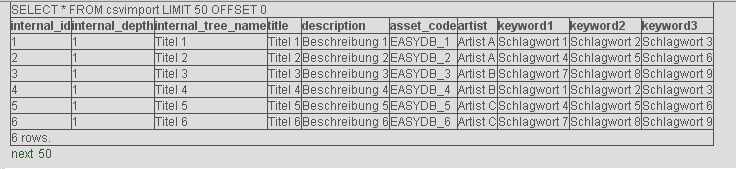
In der Vorschau werden immer 50 Zeilen angezeigt (unser Beispiel hat allerdings nur 6). Blättern Sie mit next 50 and prev 50 ( siehe 1 ).
Klicken Sie nun auf Importieren, um den Import zu starten.
Nach dem Import erscheint eine Protokoll-Seite, die etwa so aussieht:
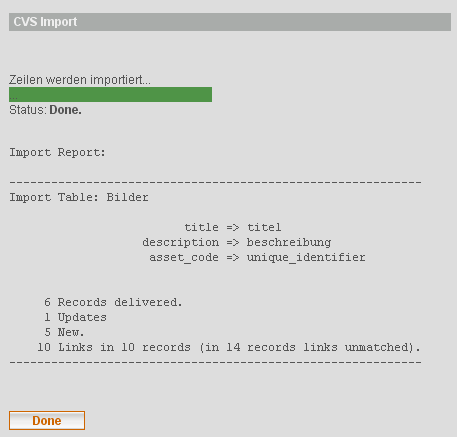
Aus technischen Gründen ist dieser Report auf Englisch.
In unserem Beispiel wurden:
Klicken Sie auf Done, um den CSV-Import abzuschließen.